Trong bối cảnh ấy, doanh nghiệp đã chuyển từ câu hỏi “Lưu dữ liệu ở đâu?” sang “Làm sao khai thác ngay khi dữ liệu còn nóng?”. Khi một chiến dịch Flash Sale trên sàn TMĐT chỉ kéo dài 2 giờ, độ trễ vài giây có thể khiến thuật toán đề xuất lỡ nhịp khách hàng. Ngân hàng số phải phát hiện gian lận thẻ tín dụng real‑time để khoá giao dịch kịp thời. Các công ty game tại TP.HCM sử dụng streaming analytics để điều chỉnh độ khó trong… 30 giây đầu chơi thử. Những yêu cầu ấy vượt xa khả năng của RDBMS truyền thống – và đó chính là lúc Big Data Engineer bước vào.
Hãy thử tưởng tượng – mỗi cú chạm màn hình, mỗi cảm biến IoT rung lên khi cửa vừa mở, hay mỗi dòng log hệ thống backend ghi lại một truy vấn SQL thất bại… tất cả đều sinh ra dữ liệu. Theo IDC, thế giới sẽ tạo ra hơn 175 zettabyte dữ liệu vào năm 2025; tức gấp 5 lần khối lượng trong năm 2018. Ở Việt Nam, thương mại điện tử vượt mốc 20 tỷ USD, các ví điện tử xử lý hàng triệu giao dịch/ngày, và mạng 5G thúc đẩy loạt thiết bị thông minh mới – tất cả đòi hỏi một hạ tầng đủ mạnh để nuốt và tiêu hoá luồng dữ liệu khổng lồ đó.
Đọc bài viết sau để hiểu rõ:
- Big Data là gì? Vì sao cần có Big Data Engineer?
- Phân biệt nhiệm vụ của Data Engineer, Big Data Engineer, Data Architect, DevOps Engineer và Cloud Engineer
- Lộ trình phát triển Big Data Engineer
Big Data là gì? Vì sao cần có Big Data Engineer?
Big Data là gì?
Big Data (dữ liệu lớn) là thuật ngữ mô tả những khối dữ liệu vừa có dung lượng khổng lồ, vừa tuôn ra với tốc độ cao và mang nhiều định dạng khác nhau. Dữ liệu này có thể đến từ log truy cập web, dòng clickstream quảng cáo, tới tín hiệu cảm biến IoT. Khi dữ liệu vượt quá sức chịu đựng của hệ thống truyền thống, doanh nghiệp cần một người thiết kế hạ tầng đủ mạnh để dữ liệu vẫn chảy thông suốt, chính xác và tiết kiệm chi phí: đó chính là Big Data Engineer.
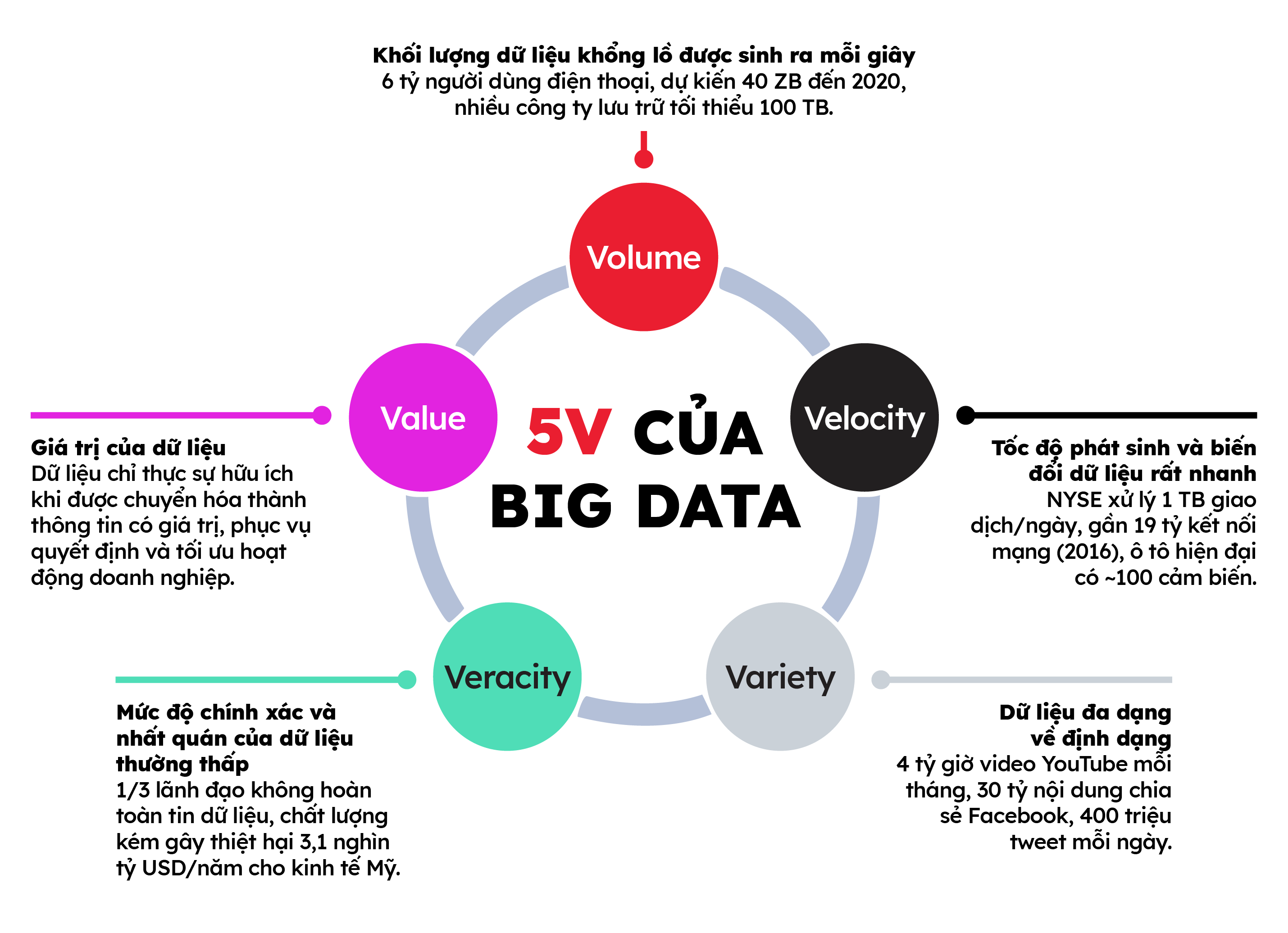
Big Data là lượng dữ liệu khổng lồ có 5V: Volume (khối lượng cực lớn), Velocity (tốc độ tuôn ra liên tục), Variety (đủ loại cấu trúc), Veracity (độ tin cậy) và Value (giá trị khai thác). Nhiệm vụ của Big Data Engineer là xây “đường ống” cho 5V ấy, đối mặt với ba thách thức chính: dữ liệu phình to nhanh hơn hạ tầng, độ trễ real‑time ngày càng khắt khe, và chi phí cloud phải giảm liên tục để không “đốt” ngân sách.
Vai trò của Big Data Engineer
Big Data Engineer đóng vai trò “kiến trúc sư dòng chảy”, xây dựng đường ống ingest thời gian thực bằng các nền tảng như Kafka hoặc NiFi, quy hoạch nơi lưu trữ tối ưu – chẳng hạn HDFS, S3 hay Iceberg – rồi tinh chỉnh những công cụ xử lý phân tán như Spark hoặc Flink để bảo đảm mọi tác vụ đạt SLA, thậm chí phục vụ API với độ trễ dưới 100 ms.
Họ phải cân đo giữa tính đúng đắn và ngân sách: chỗ nào dữ liệu buộc phải exactly-once để tránh sai lệch, chỗ nào chỉ cần at-least-once nhằm giảm chi phí hạ tầng. Không chỉ giỏi kỹ thuật, một Big Data Engineer giỏi còn cần hiểu sâu về nghiệp vụ. Họ phải biết rõ dữ liệu sẽ được dùng để làm gì – phân tích BI, huấn luyện AI, hay phục vụ sản phẩm – để thiết kế pipeline phù hợp.
Tầm quan trọng của Big Data Engineer nằm ở chỗ họ đặt nền móng cho toàn bộ hành trình “data-driven” của doanh nghiệp. Nếu dữ liệu không sạch, không cập nhật kịp hoặc quá tốn kém để vận hành, mọi phân tích và mô hình AI phía sau đều mất giá trị. Một pipeline được kiến trúc tốt không chỉ giúp doanh nghiệp ra quyết định bằng dữ liệu đáng tin cậy mà còn tiết kiệm ngân sách cloud ở quy mô hàng trăm nghìn đô mỗi năm, đồng thời tăng tốc cho ra mắt các tính năng mới – lợi thế cạnh tranh sống còn trên thị trường.
Hãy cùng đào sâu vào vai trò, kỹ năng và lộ trình để thấy vì sao vị trí này xứng đáng nằm trong “Top 3 nghề IT đáng đầu tư 2025”.
Big Data Engineer làm gì mỗi ngày?
Nếu coi dữ liệu là “dầu mỏ” thời kỹ thuật số, thì Big Data Engineer chính là kỹ sư đường ống và nhà máy lọc dầu – đảm bảo dòng “dầu thô 0‑1” liên tục chảy, được xử lý đúng chuẩn và biến thành “nhiên liệu AI/BI” giúp doanh nghiệp tăng tốc.
Công việc hằng ngày của Big Data Engineer xoay quanh 4 nhóm chính sau:
1. Xây đường dẫn dữ liệu (Build)
- Nhận dữ liệu thô từ ứng dụng, thiết bị IoT, file log…
- Dùng các công cụ như Kafka hoặc NiFi để đẩy dữ liệu vào “hồ” lưu trữ (HDFS, S3).
- Viết chương trình Spark hoặc Flink để làm sạch và biến đổi dữ liệu thành định dạng dễ dùng.
2. Giám sát và sửa lỗi (Run)
- Theo dõi dashboard: nếu dòng dữ liệu chậm hoặc cụm máy chủ quá tải thì phải điều chỉnh ngay.
- Khi có cảnh báo, kiểm tra log, tìm nguyên nhân và khởi chạy lại job nếu cần.
- Viết hướng dẫn (runbook) để lần sau cả team xử lý nhanh hơn.
3. Tối ưu và tiết kiệm (Improve)
- Gộp hoặc tách dữ liệu hợp lý để truy vấn nhanh hơn.
- Chuyển dữ liệu ít dùng sang lưu trữ giá rẻ để cắt giảm chi phí cloud.
- Đo lường độ trễ (latency) và chi phí, rồi tinh chỉnh cấu hình để “đạt chuẩn nhưng không tốn kém”.
4. Hỗ trợ và phối hợp (Collaborate)
- Làm việc với Data Analyst / Data Scientist để đảm bảo họ có dữ liệu đúng lúc, đúng nghĩa.
- Review mã của đồng nghiệp, chia sẻ mẹo tối ưu, mentoring bạn mới.
- Viết tài liệu ngắn gọn để các phòng ban hiểu luồng dữ liệu chạy ra sao.
Kết quả mà một Big Data Engineer tạo ra có thể là: một báo cáo real‑time cho team Marketing, bảng dữ liệu sạch cho AI dự đoán, hay đơn giản là giúp công ty giảm 20 % hoá đơn AWS tháng này. Tất cả đều bắt đầu từ việc bạn đảm bảo dữ liệu “chảy” đều đặn và an toàn.
Các tech‑stack “ruột” của Big Data Engineer

Năm 2025, hệ sinh thái Big Data đã lớn mạnh với hàng trăm framework khác nhau, mỗi framework lại yêu cầu mức độ thành thạo riêng. Sự đa dạng và tốc độ đổi mới này khiến việc chọn và học đúng công cụ trở thành thử thách lớn cho bất kỳ Big Data Engineer nào.
Để tránh học lan man, khi mới bắt đầu, bạn nên nắm vững các công cụ cốt lõi cho từng giai đoạn. ITviec đã giúp bạn tóm tắt theo bảng dưới đây:
| Giai đoạn | Công việc chính | Công cụ chủ lực (ví dụ) |
| Ingest – đưa dữ liệu vào | Thu thập log, event, file… theo thời gian thực hoặc định kỳ | Kafka (stream), NiFi/Flume (ETL nhẹ) |
| Storage – lưu trữ dữ liệu | Lưu trữ thô & đã xử lý, phân tầng nóng‑lạnh | HDFS (on‑prem), S3 (cloud), Iceberg / Delta Lake (table format cho schema‑evolution) |
| Processing – làm sạch & phân tích | Chạy batch ETL, xử lý stream, hỗ trợ truy vấn SQL on‑lake | Spark / Flink (batch + stream), Hive, Presto/Trino (SQL interactive) |
| Orchestration & DevOps | Lên lịch, quản lý version, deploy tự động, co giãn tài nguyên | Airflow (scheduling), Kubernetes (container), Terraform (IaC), CI/CD (GitLab, Jenkins) |
Mẹo nhớ nhanh: Kafka đưa vào, S3 cất giữ, Spark/Flink xử lý, Airflow trông coi. Chỉ bốn từ khoá nhưng đủ mô tả 80% luồng dữ liệu ở mọi công ty.
Kỹ năng mềm cần có đối với Big Data Engineer
Thành thạo Spark hay Kafka mới chỉ là “một nửa tấm vé”. Phần còn lại nằm ở kỹ năng mềm giúp bạn kết nối mọi bộ phận xoay quanh dữ liệu:
- Kỹ năng nói chuyện với business: Học cách dịch biểu đồ CPU, lag Kafka thành câu chuyện “lý do vì sao báo cáo doanh thu bị chậm” để Marketing hay Finance dễ nắm – và ngược lại, lắng nghe họ để hiểu đâu mới là chỉ số quan trọng.
- Hợp tác với Data Analyst & Data Scientist: Cùng nhau vẽ lại KPI, thống nhất định nghĩa “một đơn hàng thành công”, bảo đảm họ luôn có data sạch và kịp thời cho dashboard hay mô hình AI.
- Phối hợp Dev & Ops: Gắn lịch release, chia sẻ tài liệu hạ tầng để tránh cảnh Dev push code, Data job vỡ schema hay server quá tải giữa đêm.
- Quản lý thời gian: Biết ưu tiên, khi nào tập trung vá sự cố, khi nào dừng lại để tối ưu chi phí; dám nói “chậm lại” nếu backlog đã quá dày.
- Tự học & nghiên cứu: Đọc tài liệu technical, rồi giản lược kiến thức khó thành “bảng cheat‑sheet” cho đồng nghiệp junior.
- Giải quyết vấn đề có hệ thống: Truy đến nguyên nhân gốc (root cause), ghi lại runbook và chia sẻ rộng rãi để cả team tránh lặp lại.
Nhờ những kỹ năng mềm này, Big Data Engineer trở thành chiếc cầu nối giữa kỹ thuật và kinh doanh, bảo đảm dữ liệu không chỉ “chạy” mà còn mang lại giá trị thật.
Mức lương của Big Data Engineer có hấp dẫn không?
Mức lương Big Data Engineer ở Việt Nam
*Lưu ý: Số liệu được lấy từ Báo cáo Lương IT 2024‑2025 của ITviec. Báo cáo này chưa tách Big Data Engineer thành nhóm riêng, vì Big Data Engineer thực chất là nhánh chuyên sâu của Data Engineer, mức thu nhập thường cao hơn 10‑20 % nhờ kỹ năng xử lý dữ liệu quy mô lớn. Bảng dưới đây lấy Data Engineer (VN) làm mốc, sau đó cộng thêm ~15 % để bạn hình dung.
| Số năm kinh nghiệm | Mức lương Data Engineer | Ước tính mức lương Big Data Engineer (*) | Công việc chính |
| 0–2 y | 20–30 triệu | 23–35 triệu | Viết job Spark/Flink cơ bản, hỗ trợ ETL, học chuẩn hoá data contract |
| 2–4 y | 30–50 triệu | 35–57 triệu | Thiết kế pipeline, tối ưu query, quản lý bảng Iceberg/Delta Lake |
| 4–6 y | 50–65 triệu | 55–75 triệu | Scale cluster, mentor team, giảm chi phí S3/Kafka, đảm bảo SLO streaming |
| 6 y+ | 80 triệu+ | 90 triệu+ | Kiến trúc dữ liệu lớn, budgeting, roadmap dữ liệu toàn công ty |
| 8 y+ | Thỏa thuận | Thỏa thuận | Chiến lược dữ liệu, quản lý P&L, làm việc với lãnh đạo C‑level |
Tại sao lương Big Data Engineer lại cao hơn? Do Big Data Engineer thường làm việc ở các doanh nghiệp có dòng dữ liệu “khổng lồ” (click‑stream, IoT, quảng cáo real‑time), họ sẵn sàng trả lương cao để thuê người “giữ hệ thống không nghẽn hơi”. Trong khi Data Engineer truyền thống thường làm việc ở các công ty chỉ cần xử lý dữ liệu ở quy mô GB.
Mức lương Big Data Engineer ở Hoa Kỳ
Theo Glassdoor, lương Data Engineer ở Mỹ có tổng thu nhập trung vị ~134 000 USD/năm; lương Big Data Engineer ở Mỹ thường vượt mốc này 10‑15 %. Khoảng chênh lệch thể hiện độ khan hiếm nhân lực hiểu sâu Spark/Flink ở quy mô petabyte.
Làm thế nào để tăng lương?
Càng lên cao, chứng chỉ Cloud (AWS Big Data, GCP Professional Data Eng) và kỹ năng tối ưu chi phí S3/EMR sẽ giúp Big Data Engineer thương lượng được mức lương tốt. Ngoài ra, kỹ năng mềm (giao tiếp liên phòng ban, quản lý thời gian) là “đòn bẩy” hiệu quả giúp bạn dễ dàng bước sang Lead hoặc Architect.
Đọc thêm:
Nếu bạn muốn đào sâu hơn lộ trình phát triển và mức lương chi tiết của Data Engineer nói chung, hãy xem bài viết chuyên sâu Lộ trình Data Engineer và bài Lương Data Engineer trên blog ITviec – nguồn tham khảo đầy đủ số liệu và gợi ý thăng tiến.
Big Data Engineer khác gì với Data Engineer?
Nếu bạn đang đứng trước hai sự lựa chọn: Data Engineer (DE) và Big Data Engineer (BDE), thì bạn cần hiểu rằng: Khác biệt lớn nhất không nằm ở “dùng công cụ gì” mà ở quy mô công ty và túi tiền họ sẵn sàng chi cho vị trí đó.
| Yếu tố | Data Engineer (DE) | Big Data Engineer (BDE) |
| Khởi điểm phù hợp | Sinh viên IT, Tester, BI Analyst muốn học thêm SQL, ETL | DE đã vững muốn “lên level”, DevOps/Cloud Engineer chuyển sang dữ liệu lớn |
| Lương khởi điểm | 20–30 triệu VNĐ/tháng | 23–35 triệu VNĐ/tháng (≈ +15 %) |
| Trần lương (Senior) | ~65 triệu | ~75 triệu (+ kỹ năng Cloud, streaming) |
| Lĩnh vực phổ biến | Startup, SME, E-commerce quy mô vừa, doanh nghiệp cần báo cáo | FinTech, AdTech, Telco 5G, Big Tech, công ty “ngàn tỷ” dữ liệu |
| Rủi ro thay thế | Thấp – luôn cần người làm ETL, quản trị DWH | Vừa – nếu công ty giảm quy mô dữ liệu, nhu cầu BDE giảm theo |
| Tốc độ thăng tiến | 2–3 năm lên Senior | Nhanh nếu chịu học sâu Spark/Flink + Cloud |
| Gợi ý học thêm | Cloud basics, Python nâng cao | Streaming, tối ưu chi phí cloud, chứng chỉ Big Data |
Có phải công ty lớn nào cũng cần Big Data Engineer hay chỉ cần Data Engineer?
Đôi khi doanh nghiệp phải xử lý khối lượng dữ liệu lớn, nhưng cũng có những lúc dữ liệu chỉ ở quy mô nhỏ đến vừa. Khi đó, các giải pháp Big Data thường trở nên cồng kềnh, tốn kém và phức tạp để triển khai. Trong nhiều trường hợp, chỉ với một hệ thống dữ liệu đơn giản, xuất ra file Excel là đã đủ đáp ứng nhu cầu.
Khi dữ liệu đã trở thành “tài sản sống” của doanh nghiệp, từng bước trong chuỗi: thu thập (ingest) → lưu trữ → xử lý → phục vụ đều cần có người chịu trách nhiệm rõ ràng. Từ yêu cầu chuyên môn hóa này, nhiều chức danh nghe có vẻ na ná nhau ra đời, nhưng mỗi vị trí lại khác biệt về mức độ kỹ thuật, phạm vi ảnh hưởng và tiêu chí đánh giá.
Cả doanh nghiệp lẫn ứng viên IT đều cần hiểu rõ: khi nào cần tuyển Big Data Engineer, khi nào chỉ cần Data Analyst hay Data Engineer… để đảm bảo “đúng người – đúng việc”.
Cụ thể các chức danh liên quan đến dữ liệu bao gồm:
- Data Engineer (DE) là người dựng những đường ống ETL/ELT và mô hình hoá schema nhằm bảo đảm dữ liệu luôn sẵn sàng cho BI. Thành công của họ thường đo bằng SLA: ví dụ một pipeline batch phải chạy xong trong vòng một giờ, bảng fact phải được làm mới đúng lịch.
Data Engineer xuất hiện khi doanh nghiệp đã có data warehouse hoặc lakehouse, cần báo cáo chuẩn hoá; ngược lại, nếu công ty chỉ lưu vài Google Sheet và truy vấn thủ công, gọi vị trí Data Engineer đôi khi chỉ “để cho oai”.
- Khi lượng dữ liệu phình lên tới hàng terabyte hoặc cần phân tích theo thời gian thực, Big Data Engineer bước vào cuộc chơi. Họ tối ưu cluster Spark hoặc Flink, thiết kế streaming với độ trễ dưới một giây và canh chừng chi phí cho từng nút máy.
Công ty quảng cáo real-time bidding, IoT hay telco 5G thường phải có Big Data Engineer, trong khi tổ chức chỉ chạy batch hằng ngày với dữ liệu dưới một terabyte thì chưa thực sự cần.
- Lớp ở cao hơn là Data Architect – người vẽ bức tranh tổng thể, chuẩn hoá data contract, giảm trùng lặp và quản lý lineage. Khi doanh nghiệp có nhiều domain và nguồn dữ liệu hỗn độn, họ cần kiến trúc sư kiểu này để triển khai data mesh; còn các start-up sở hữu vỏn vẹn ba nguồn, schema đơn giản, thường chưa cần tới.
- Bên phía hạ tầng, DevOps Engineer bảo đảm mã nguồn và hạ tầng “lên production” êm ru, từ CI/CD đến monitoring. KPI của họ thường xoay quanh tỷ lệ deploy thành công trên 95% và thời gian khắc phục sự cố (MTTR) dưới nửa giờ. Nếu ứng dụng vẫn là monolith nhỏ, deploy tay chưa phải vấn đề, gán thêm DevOps vào JD đôi khi lại thừa.
- Cuối cùng là Cloud Engineer, người giữ vững 99,9% uptime và tiết kiệm ít nhất 20% chi phí mỗi năm trên AWS, GCP hay Azure. Vai trò này phát huy tối đa khi workload chạy hoàn toàn trên public cloud; còn hệ thống on-prem nhỏ, tải cố định thường không cần chuyên gia riêng.
Vì sao các công ty cần gọi đúng chức danh?
Đặt tên chức danh đúng với vai trò mang lại ba lợi thế lớn:
- Thứ nhất, tuyển dụng chuẩn xác: HR lọc CV nhanh, ứng viên biết mình có phù hợp hay không, giảm bớt những vòng phỏng vấn không cần thiết.
- Thứ hai, ranh giới trách nhiệm mạch lạc: Spark job bất ngờ chậm, cả team nhìn vào sơ đồ ownership là biết phải gọi ai.
- Thứ ba, nhân viên nhìn thấy lộ trình thăng tiến: từ Junior Data Engineer lên Big Data Engineer rồi Architect, không mơ hồ chuyện “lớn lên sẽ làm gì”.
Thách thức của việc đặt tên
Tuy vậy, việc đặt tên cũng đầy thử thách. Nhiều vai trò “lai” – chẳng hạn vừa viết ETL vừa quản trị hạ tầng – khiến công ty khó xếp vào hộp nào, dẫn tới JD gộp mơ hồ kiểu “Full-stack Data Engineer”. Khi doanh nghiệp pivot sản phẩm, Big Data Engineer bỗng kiêm luôn DevOps nhưng title không đổi, dễ tạo khoảng cách kỳ vọng giữa nhân viên và quản lý. Thêm vào đó, thị trường định nghĩa lương mỗi chức danh rất khác nhau; cùng một title, mức đãi ngộ ở start-up series A có thể thấp hơn tập đoàn lớn cả bậc, khiến ứng viên ngộ nhận.
Nếu ngân sách còn hạn hẹp, lời khuyên là tuyển một Data Engineer “đa năng” kèm lộ trình nâng cấp title khi hệ thống lớn dần. Cách làm này linh hoạt, tránh đặt tên cho thật kêu rồi sau phải mất thời gian giải thích lại – vừa đỡ kỳ vọng lệch, vừa không “thổi phồng” vai trò khi chưa thực sự cần.
Câu hỏi thường gặp về Big Data Engineer
Big Data Engineer có cần biết Machine Learning?
Không bắt buộc, nhưng hiểu cách mô hình ML “ăn” dữ liệu sẽ giúp bạn làm việc trơn tru với Data Scientist. Hãy nắm khái niệm feature store, ML‑ops pipeline và cách xuất dữ liệu realtime cho mô hình – vậy là đủ để gây ấn tượng khi phỏng vấn.
Không có bằng ĐH CNTT theo nghề được không?
Hoàn toàn được. Rất nhiều BDE xuất thân từ toán‑thống kê hoặc điện‑điều khiển. Lộ trình phổ biến: tự học Python + SQL cơ bản → khoá online Spark/Flink → lấy chứng chỉ Cloud Practitioner → thực hành dự án cá nhân (ETL Twitter API vào S3). Nhà tuyển dụng đánh giá cao dự án thật hơn tấm bằng.
Big Data Engineer khác gì Data Scientist?
Hãy hình dung BDE là thợ xây hệ thống nước, còn Data Scientist là đầu bếp. Đầu bếp giỏi cũng phải có nước sạch đúng lúc; BDE cung cấp “nước sạch” (dữ liệu chất lượng, giá rẻ, tốc độ cao) để Data Scientist nấu món insight/AI. Công việc ít chồng lấn nên hai vị trí này có thể phối hợp chặt.
Nên học Hadoop hay nhảy thẳng Spark/Flink?
Hadoop MapReduce như xe tải đời cũ – hữu ích để hiểu gốc rễ nhưng không còn được đặt hàng nhiều. Spark là bước đệm batch‑&‑micro‑batch dễ học, Flink là “tay đua F1” cho streaming realtime. Vì vậy, thứ tự khuyên dùng: nắm khái niệm MapReduce → làm dự án Spark → trải nghiệm Flink.
Thị trường việc làm Big Data Engineer 2025 tại Việt Nam?
Nhu cầu tuyển dụng cho vị trí này đang bùng nổ ở FinTech, thương mại điện tử và Telco 5G. Theo khảo sát nội bộ ITviec, số tin tuyển dụng vị trí BDE 2024 tăng 35 % so với 2023. Nhờ dịch vụ cloud giá rẻ, cả doanh nghiệp vừa SMB cũng bắt đầu tuyển BDE part‑time để tối ưu chi phí S3 hoặc dựng realtime dashboard.
Tổng kết
Tóm lại, cơn “sóng thần” dữ liệu vẫn đang dâng cao từng ngày và Big Data Engineer chính là người lướt trên ngọn sóng ấy. Dù bạn xuất phát từ phòng lab đại học hay đã có vài năm làm ETL, con đường bước vào thế giới dữ liệu khổng lồ luôn rộng mở: chỉ cần vững Python, chắc SQL và không ngại cầm cờ tìm hiểu công nghệ mới. Khi bạn giúp doanh nghiệp biến hàng tỷ dòng log thành insight và hành động, giá trị bạn mang lại sẽ phản ánh trực tiếp vào mức lương, uy tín và cơ hội thăng tiến.
Hãy bắt đầu từ những bước nhỏ nhưng đều đặn: dựng một project mini trên GitHub, theo dõi các bản tin tech, hỏi “tại sao” sau mỗi con số, rồi ứng tuyển công việc đầu tiên tại ITviec. Mọi hành trình dài đều khởi đầu bằng một query SELECT đầu tiên – và biết đâu, chính bạn sẽ là người tối ưu nó xuống còn vài mili‑giây. Thế giới Big Data đang đợi, và vị trí kỹ sư dữ liệu lớn tương lai có thể đang gọi tên bạn ngay hôm nay.